 (1).png) 10 months ago
458864
10 months ago
458864
ARTICLE AD BOX
This is Decrypt’s co-founder, Josh Quittner, having a casual meeting with his friend, Vitalik Buterin.

No, not really. They’ve never met, much less been in the same place at the same time. This image is a fake, which isn’t surprising. What is surprising is that it took us less than a minute to build, using two photos and a simple prompt: “The man from image 1 and the man from image 2 posing for the cameras in a bbq party.” Pretty nifty.
The model is Omnigen, and it’s a lot more than just an image generator. Instead, it focuses on image editing and context understanding, letting users tweak their generations by simply chatting to the model, rather than loading standalone third-party tools. It is capable of “reasoning” and understanding commands thanks to its embedded LLM.
Researchers at the Beijing Academy of Artificial Intelligence have finally released the weights—the executable AI models that users can run on their computer—of this new type of AI model that may be an all-in-one source for image creation. Unlike its predecessors, which operated like single-purpose task executors (having artists load separate image generators, controlnets, IPadapters, inpainting models, and so on) OmniGen functions as a comprehensive creative suite. It handles everything from basic image editing to complex visual reasoning tasks within a single, streamlined framework.
OmniGen relies on two core components: a Variational Autoencoder—the good old VAE that all AI artists are so familiar with—that deconstructs images into their fundamental building blocks, and a transformer model that processes varied inputs with remarkable flexibility. This stripped-down approach eliminates the need for supplementary modules that often bog down other image generation systems.
Trained on a dataset of one billion images, dubbed X2I (anything-to-image), OmniGen handles tasks ranging from text-to-image generation and sophisticated photo editing to more nuanced operations like in-painting and depth map manipulation. Perhaps most striking is its ability to understand context. So for example when prompted to identify a place to wash hands, it instantly recognizes and highlights sinks in images, showcasing a level of reasoning that approaches human-like understanding.

In other words, unlike any other image generator currently available, users can “talk” to Omnigen in a similar way they would interact with ChatGPT to generate and modify images—no need to deal with segmentation, masking, or other complex techniques, since the model is capable of understanding everything simply via commands.
So, basically imagine telling an open source model to create a winter coat with herringbone pattern, add fur trim, and adjust the length—all in one go. If you don’t like it, you can simply prompt “make the coat white” and it would understand the task without you having to manually select the coat, load a new model, prompt “white coat” and pray for the coat to look similar to your generation—or opening photoshop and having to deal with some color manipulation.
This is a pretty significant breakthrough.
One of the interesting achievements of this new model is that OmniGen has Microsoft’t Phi-3 LLM embedded and researchers trained the model to apply a chain-of-thought approach to image generation, breaking down complex creative tasks into smaller, more manageable steps, similar to how human artists work. This methodical process allows for unprecedented control over the creative workflow, though researchers note that output quality currently matches rather than exceeds standard generation methods.
Looking ahead, researchers are already exploring ways to enhance OmniGen's capabilities. Future iterations may include improved handling of text-heavy images and more sophisticated reasoning abilities, potentially leading to even more natural interaction between human creators and AI tools.
How to run Omnigen
Omnigen is open source, so users can run it locally. However, users have a few free generations thanks to Hugging Face—the world’s largest open source AI community/repository—so they can use its servers to test the model in case they don’t have the required hardware.
Those who don’t want to bother a lot with the model can go to this free Hugging Face Space and play around with the model. It will open a very intuitive UI.
Basically, the model can handle up to three images of context and a nice amount of text input. It also shows a very detailed set of instructions to generate or edit images. If you are new to it, do not bother a lot with all the parameters. Simply insert the image (or images) you want to the program to edit or use as inspiration, and prompt it in the same way you would do with ChatGPT, using natural language.
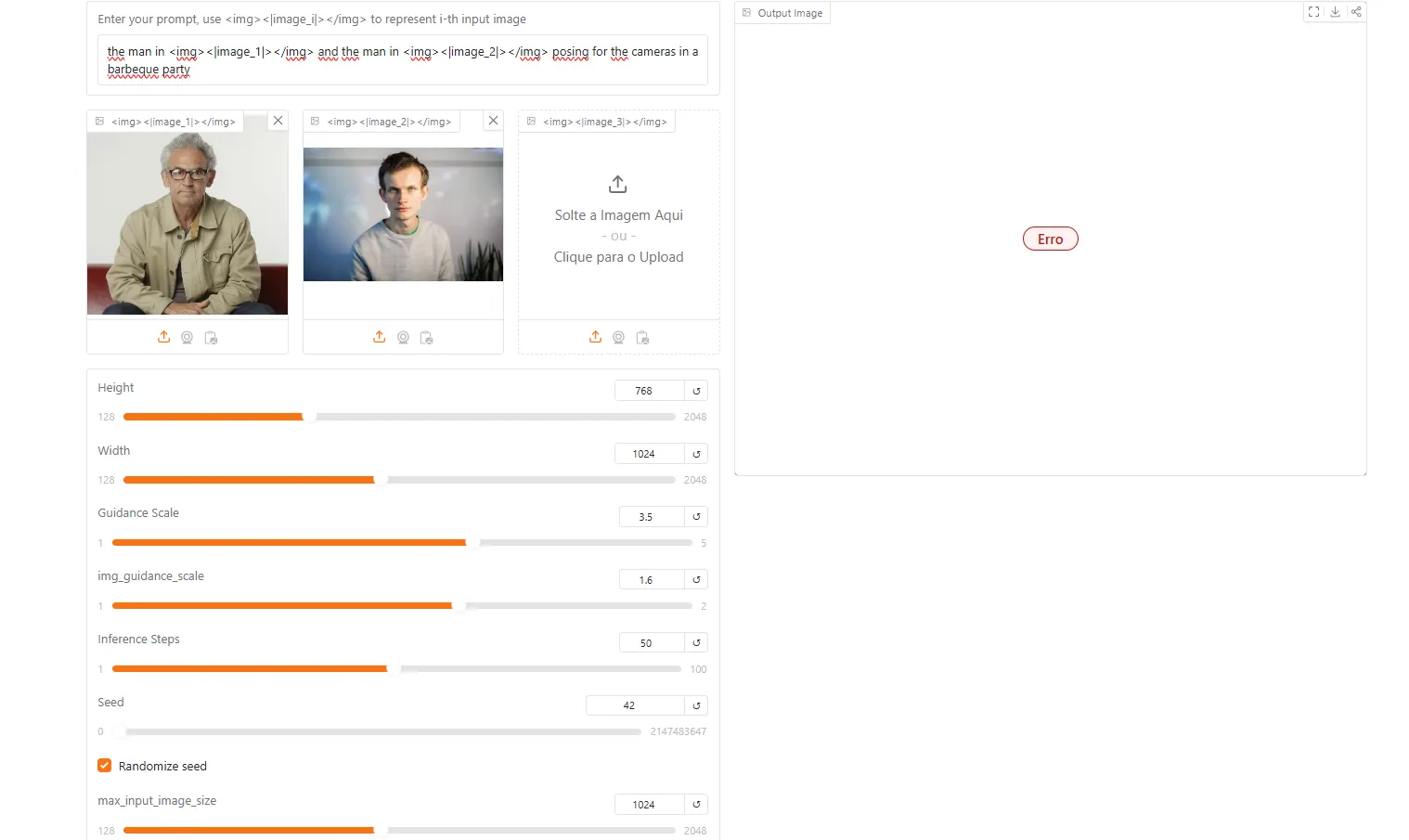
However, those willing to generate images locally will have to download the weights, and some libraries. Considering its capabilities, it is expected to require a lot of VRam to run. Some reports show the model runs fine on 12GB of VRam and is only compatible with Nvidia cards for now.
To install the models locally, simply follow the instructions provided on the Github page: Basically, create a new installation folder, clone the github repository, install the dependencies, and you’re good to go. To have a nice UI instead of using just text, install the Gradio Interface, following the steps provided in the Github page. Alternatively, you can follow this tutorial in case you prefer video instructions.
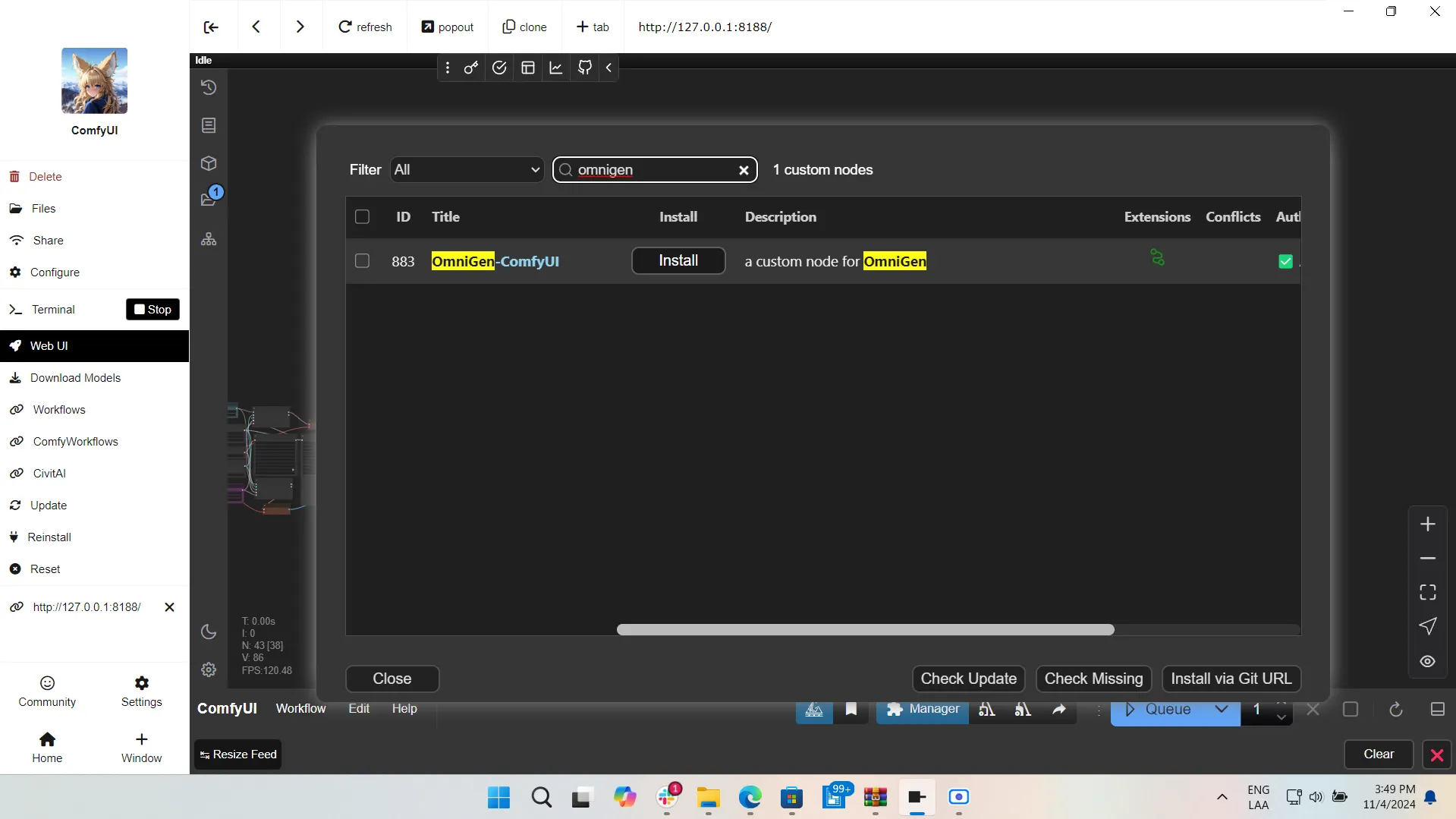
If you are a bit more experienced, you can use ComfyUI to generate images. To install Omnigen, simply go to the download manager, search for the Omnigen node and install it. Once you are done, restart ComfyUI, and that’s it. When executed, the node itself will download the weights.
We were able to test the model, and it takes considerably longer to generate images when compared against SD 3.5 or Flux. It’s strength is not quality but accuracy, meaning, some images may lack details or realism, but will show high levels of prompt adherence, especially when dealing with natural language prompts in edits.
At its current state, Omnigen is not a good image generator for those looking for a model capable of beating Flux or SD 3.5. However, this model does not intend to be that.
For those looking for an AI-powered image editor, this is probably one of the most powerful and user-friendly options currently available. With simple prompt commands, it achieves similar results to what professional AI artists get with very complex workflows, dealing with highly specialized tools.
Overall, the model is a great alternative for beginners who are testing the waters of Open Source AI. However, it could be great for professional AI artists if they combine its powerful capabilities into their own workflows. It could also drastically simplify workflows from dozens of different nodes or passes to a single generation with a few less elements to run and load.
For example, using it as a primary source to merge different elements into a composition and then denoising that result so it can go through a second pass with a more powerful AI model could prove a very good and versatile solution to achieve great generations.
Generally Intelligent Newsletter
A weekly AI journey narrated by Gen, a generative AI model.









 English (US) ·
English (US) ·